Share on
構造化データとは?AIO対策に必須の理由と実装方法を徹底解説

Google検索に「AI Overviews(AIによる要約回答)」が本格導入され、検索体験は大きな転換期を迎えています。この流れに伴い、LLMO/AIO対策の必要性が注目される中、Webサイトが「AIに選ばれる」ための絶対条件となりつつあるのが「構造化データ」の実装です。
AIの回答で検索を完結させる「ゼロクリック検索」が主流になる中、構造化データは「AIに自社の情報を正しく引用させるための必須言語」であり、AIO/LLMO対策の前提として業界のスタンダードになりつつあります。
- AI Overviewsにより、自社サイトへの流入が減るのでは
- これまでのSEO対策だけでは不十分なのでは
- 「AIO対策」という言葉を聞くが、何から始めればよいのか分からない
本記事ではこういった不安を抱えている方に向けて、まず着手すべき最短ルートである構造化データについて、専門用語を噛み砕きながら解説していきます。
- 構造化データとは何か、なぜ今重要なのか
- AI検索(AIO)時代において、構造化データが果たす役割
- 優先して実装すべき構造化データの種類
- エンジニアに依頼する際に最低限押さえておくべき知識
- 実装後の検証方法と、よくあるエラーへの対処法
「難しそうだから」と後回しにできない、AI時代のサイト運用の基礎知識をここでアップデートしましょう!
構造化データとは
構造化データとは、Webページの内容を検索エンジンやAIが正確に理解できるように、意味や文脈をデータとして明示する仕組みのことです。
通常のHTMLは、「ここが太字」「ここは箇条書き」といった見た目の構造を伝えることはできますが、そこに書かれた数字が「価格」なのか「電話番号」なのかといった、内容の意味までは十分に伝えられませんでした。そこで、構造化データを用いることで、「これは価格」「これは著者名」という内容の意味をAIに正確に伝えることができます。
近年のAIO/LLMO対策において、構造化データは「あると良いもの」ではなく、「前提条件」に近い存在になりつつあるため、この記事を読んで、最低限の対策でも着手できるようにしていきましょう。
構造化データの役割
従来のHTMLとの比較で、構造化データの役割を整理していきましょう。
HTMLは主にブラウザ向けに指示を出す役割を担っており、
- <h1> は見出し
- <p> は段落
といったように、表示上の役割を伝えることが目的でした。しかしHTMLだけでは、
- これは商品の価格なのか
- これはイベントの開催日時なのか
- これはFAQの質問と回答なのか
といった「意味的な情報(セマンティクスと言います)」までは十分に伝えられませんでした。構造化データは、こうした意味的な情報をJSON-LDなどの形式で明示的に記述し、検索エンジンやAIに直接伝える、という役割を担っています。
| 役割 | ・コンテンツの意味を正確に伝える ・検索結果やAI回答での扱われ方を最適化する |
AIO/LLMO対策に構造化データの実装が重要な理由
前章で触れたように、構造化データは検索エンジンやAIに情報の意味を正確に伝えるための仕組みです。ここからは、それがなぜAIO/LLMO対策において欠かせないのかを整理していきます。
そもそもAIO/LLMO対策とは何か
AIO/LLMOとは、生成AIが自社コンテンツを正確に理解し、回答の中で適切に引用・参照できるようにするための取り組みを指します。この取り組みの重要性が高まっている背景には、AI Overviewsの登場やゼロクリック検索の拡大が関係しています。AI Overviewsでは、検索結果の最上部にAIが生成した回答が表示され、ユーザーはその要約だけで疑問を解決するケースが増えています。また、AIが直接回答を提示することで、ユーザーが検索結果をクリックしない「ゼロクリック検索」も一般化しつつあります。
つまり、これまでのように「検索順位を上げる」だけでは、流入を確保できなくなっているのです。
AIO/LLMO対策については、こちらの記事で詳しく解説しています。

AIO対策の始め方とは?AI検索で自社サイトを表示させる実践ガイド
構造化データがAIO/LLMO対策に不可欠な理由
では、なぜ構造化データの実装がAIO/LLMO対策において不可欠なのでしょうか。
その理由は、AIが回答を生成する際に「どの情報を、どのサイトから引用するか」を判断するための基本的な情報が構造化データだからです。基本的な情報とは例えば下のようなものがあります。
- コンテンツの種類(記事、FAQ、商品情報など)
- 情報の信頼性や発信元の明確さ
- 質問と回答の対応関係
このような情報をAIに正確に理解させることで、AIが自社サイトを正しく評価し、回答の根拠として引用する可能性が高まっていきます。逆に構造化データがない場合、AIは文脈を誤って解釈したり、情報を利用しても引用元として明示しなかったりするリスクがあるため、構造化データは「必須の対策」となりつつあるわけです。
構造化データの3つのメリット
ここからは実際に構造化データを導入すると、どのような効果が得られるのかを確認していきます。AI検索時代における具体的なメリットを3つに整理して解説します。
- 生成AIからの最適な引用
- リッチリザルトの表示
- E-E-A-Tの補強
生成AIからの最適な引用
これまで説明してきたように、構造化データでは「このページはどんな種類の情報を扱っているか」をAIに正確に伝えることができます。
例えば、
- FAQPage(よくある質問)
- HowTo(手順の説明)
- Article(記事コンテンツ)
のように情報の種類を明確にすることで、ページの目的や構成をAIに正確に伝えられます。これにより、質問と回答の関係性や、手順の流れ、記事の主題が明確になり、AIが「どの部分を回答の根拠として引用すべきか」を判断しやすくなります。
結果として、
- AIからの被引用率の向上
- ブランド名の言及回数の増加
- 指名検索の増加
といった効果が期待できます。
リッチリザルトの表示
検索結果にリッチリザルトが表示される可能性が高まることも、構造化データの大きなメリットです。リッチリザルトとは、通常の青いリンクと説明文だけの検索結果に加えて、画像、評価スター、価格、所要時間など、様々な情報を追加した特別な表示形式です。
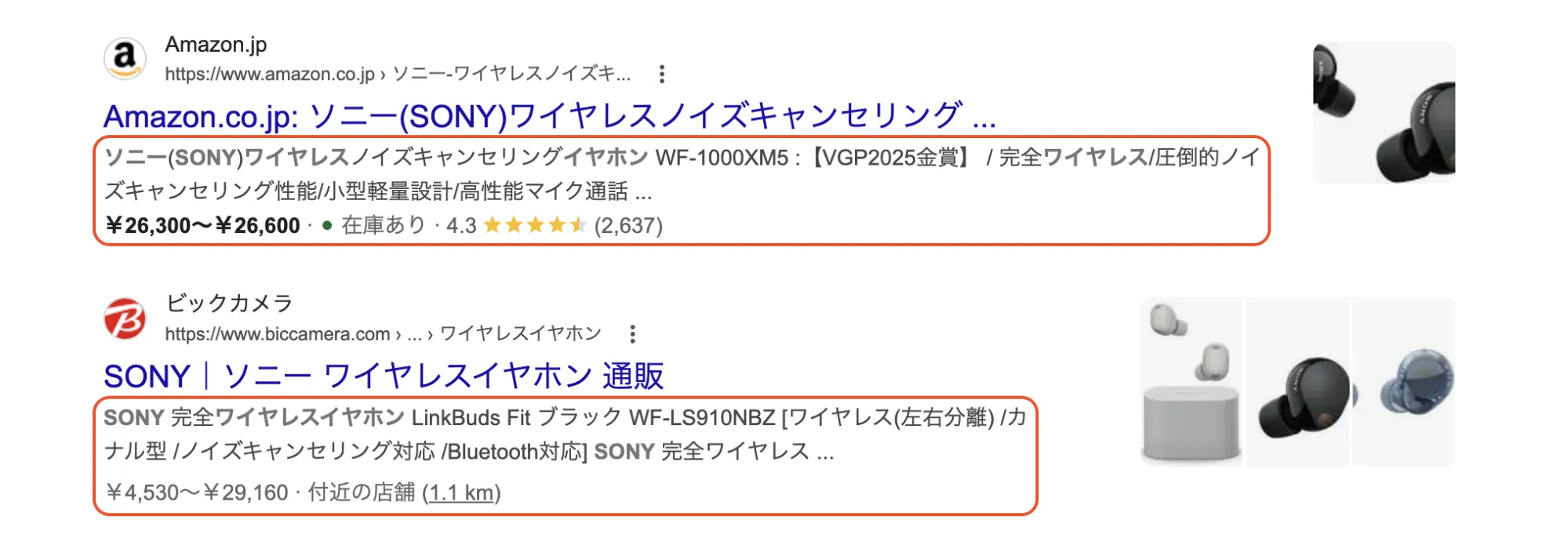
たとえば以下のような要素が挙げられます。
- 星評価(レビューの平均スコア)
- 価格や在庫状況
- 商品画像やサムネイル
- 所要時間や手順の概要
繰り返しになりますが、構造化データの実装により検索エンジンがページ内の情報を正確に理解できるようになることで、リッチリザルトが表示されるようになります。これらが表示されることで、ユーザーは検索結果一覧の段階で内容を把握しやすくなり、クリック前の理解度と信頼感が向上します。結果としてCTR(クリック率)の上昇や、ブランドの認知拡大につながっていきます。
E-E-A-Tの改善
E-E-A-Tとは、Googleがコンテンツの信頼性を評価するために重視している4つの要素です。
- Experience(経験)
- Expertise(専門性)
- Authoritativeness(権威性)
- Trustworthiness(信頼性)
構造化データを活用することで、これらの要素を検索エンジンに明確に伝えることができます。たとえば、著者情報や所属組織、連絡先、発行日などを正しくマークアップすることで、情報の出所や責任の所在を明示できます。これにより、AIや検索エンジンが「誰が、どの立場で発信しているのか」を理解しやすくなり、結果としてサイト全体の信頼性向上につながります。
構造化データの仕組み:ボキャブラリとシンタックスとは
ここからは、構造化データのより詳細な仕組みについて解説していきます。まずは前提知識として、構造化データを構成する2つの要素である「 ボキャブラリ」と「シンタックス」について説明します。この2つを理解することで、構造化データの全体像がより明確になると思います。
| 要素 | 役割 | 内容 | 具体例 |
| ボキャブラリー | 辞書 | データの意味を定義したもの。 「『name』は人の名前」 「『howto』は手順」 「『address』は住所」 のように、データの意味が定義されたもの。 AIはこれを参照する。 | Schema.org |
| シンタックス | 記述方法のルール | ボキャブラリーで定義した情報を、HTMLに書き込む時のルール(規格)。 | JSON-LD |
ボキャブラリー
ボキャブラリーとは、構造化データで「何についての情報なのか」を定義した辞書のようなものです。
たとえば、人の名前なら 「name」、手順示す場合は 「howto」、住所なら 「address」 といったように、データの意味が定義されており、検索エンジンに情報の意味を伝える役割を果たします。
代表的なボキャブラリーとして Schema.org があり、Google・Yahoo!・Microsoft など主要な検索エンジンが共同で整備しています。
Schema.org では、記事、商品、イベントなど多様なタイプやプロパティ(※タイプとプロパティは後ほど解説します)が定義されており、これを活用することで検索エンジンがページ内容をより正確に理解できるようになります。詳細は、Google検索セントラルのドキュメントでも紹介されているので、実装前に確認しておくとよいでしょう。
シンタックス
シンタックスは、ボキャブラリーで定義した情報を、実際にHTMLへ組み込む際の記述方法を指します。
主なシンタックスには以下の3種類があります。
- JSON-LD
- Microdata
- RDFa
この中で、Googleが推奨しているのはJSON-LDです。JSON-LDは2014年にW3C勧告となった形式で、HTMLの構造を崩さずにデータを追加できるのが特徴です。コードの保守性が高く、既存のページデザインに影響を与えにくいため、現在では最も一般的な実装方法として採用されています。では次に、代表的なボキャブラリーとシンタックスとして紹介した「Schema.org」と「JSON-LD」について、実際の例を交えながら詳しく見ていきましょう。
ボキャブラリー:schema
Schema.orgは、検索エンジンが共通で理解できるボキャブラリを定義したもので、「タイプ(@type)」と「プロパティ(property)」という二つの要素で構成されています。
タイプで「情報の種類」を、プロパティで「その情報が持つ属性や内容」を定義します。
| 要素 | 説明 | 例 |
| タイプ(@type) | 情報の種類を示す | ・Article(記事) ・Product(商品) ・Event(イベント) など |
| プロパティ(property) | タイプに属する具体的な属性を示す | Articleの場合は、 ・headline(見出し) ・author(著者) ・datePublished(公開日)など |
例:記事ページ(Article)に構造化データを実装する場合は、下の画像のような構成になります。

このように、Schema.orgの語彙を使うことで、AIは「これは記事であり、著者は誰で、いつ公開されたのか」を正確に理解できます。
シンタックス:JSON-LD
JSON-LDは、構造化データを記述するためのシンタックスのひとつで、現在Googleが最も推奨している形式です。HTMLの本文とは独立して記述できるため、デザインやレイアウトに影響を与えずに実装できるのが特徴です。
JSON-LDの特徴
- HTMLと分離できる
- 保守・更新が容易
- 実装ミスが起きにくい
例:JSON-LDの基本構造
JSON
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "Coosy株式会社",
"url": "https://coosy.co.jp",
"logo": "https://coosy.co.jp/logo.png"
}
</script>
このように、JSON-LDはHTML内の<script>タグに直接埋め込むだけで、検索エンジンが容易に読み取れる構造化データを用意することができます。
AIO対策で優先して対応すべき構造化データ
ここまでで、構造化データの重要性や仕組みを理解してきました。では実際に、AIO/LLMO対策としてどのような構造化データを実装すべきなのか。ここからは、具体的な種類と、その特徴を見ていきます。
構造化データには、非常にたくさんの種類があるため、一度ですべてに対応しようとするのは、少し無理があります。そのため今回は、時間がなくても最低限対応しておくべき最重要の構造化データに絞って紹介していきます。
- FAQPage
- Organization
- Article / NewsArticle
- HowTo
- LocalBusiness
すべてを一度にやる必要はありませんので、ゆっくり対応していきましょう。
FAQPage(FAQ情報)
FAQPage(FAQ情報)は、ページ内の「よくある質問」と「その回答」を示します。これにより、検索結果に質問と回答が直接表示される「FAQリッチリザルト」が出る可能性が高まります。加えて、AI検索においても、質問と回答のペアが明確に定義されているため、AIが正確に引用しやすくなるため、AIO対策として最も効果的な構造化データの1つです。優先的に取り組むようにしましょう。
Organization(組織情報)
Organization(組織情報)は、企業や団体の公式情報を伝えるものです。
会社名、ロゴ、所在地、連絡先、SNSアカウントなどを明示することで、信頼性(E-E-A-T)の強化につながります。AIが情報源を選定する際に「公式情報」として認識されやすくなるため、ブランドの信頼性を高めるうえでも欠かせません。
Article / NewsArticle(記事情報)
Article / NewsArticle(記事情報)は、ブログ記事やニュース記事などのコンテンツに使用します。
タイトル、著者、公開日、更新日、画像などを明示することで、検索結果にリッチな表示が可能になります。AIが記事の内容を要約・引用する際にも、出典情報を正確に紐づけることができるため、AIO時代のコンテンツ発信には必須です。
HowTo(手順)
HowTo(手順)は、「手順を説明するコンテンツ」に用いられます。
手順の順番、必要な道具、所要時間などを構造化することで、検索結果にステップごとの表示が可能になります。AIへの質問には「〜のやり方を教えて」という質問が多くみられるため、手順を説明した情報であることを示すことで、AIに引用される可能性を高めることにつながります。
LocalBusiness(ローカルビジネス)
LocalBusiness(ローカルビジネス)は、店舗や事業所などの地域ビジネス向けです。住所、営業時間、電話番号、地図情報などを明示することで、Googleマップやローカル検索での露出が向上します。AIが「近くの○○」といった検索に回答する際に、地域情報を正確に認識させるために非常に重要です。
構造化データの実装方法
ここからは、実際に「どうやって実装すればいいのか」を見ていきましょう。実装方法は大きく分けて次の2つがあります。
- HTMLに直接記述する方法
- CMSやプラグインを利用する方法
それぞれにメリット・デメリットがあり、サイトの規模や運用体制によって最適な選択肢は異なってくるため、自社のケースを考えながら両方の特徴を理解していきましょう。
HTMLに直接マークアップ
この方法は、構造化データをJSON-LD形式で記述し、HTMLドキュメントの<head>タグ内、または<body>タグ内の適切な位置に直接埋め込む方法です。
- Schema.orgを参照し、対象のページタイプ(例: Organization, Product)に必要なプロパティを確認。
- JSON-LD形式で構造化データコードを記述。
- 完成したコードを、<script type="application/ld+json"> タグで囲む。
- HTMLファイルに貼り付ける。
最もシンプルで、コードの追加が簡単です。既存のHTMLマークアップを汚染しないため、保守性が高いですが、一方で大量のページや動的なコンテンツを持つページでは、手動での記述・管理が煩雑になりがちです。
マークアップ支援ツールを用いる
特にWordPressなどのCMS(コンテンツ管理システム)を使用している場合や、手動での記述に不安がある場合は、公式またはサードパーティ製の支援ツールを利用します。
サードパーティ製プラグイン(例: Yoast SEO、Schema Proなど)が、WordPressユーザーの中では一般的な方法です。プラグインを導入し、設定画面でサイト全体の情報(Organizationなど)や、ページの種類ごとのテンプレートを設定するだけで、JSON-LDコードが自動生成され、各ページに挿入されるため、こちらも非常におすすめです。
【コードサンプル付き】構造化データ実装の手順
ここでは、AIO対策の基盤となる「組織情報(Organization)」を例に、構造化データを実装する具体的な手順を解説します。JSON-LD形式で、どの情報を整理し、どのようにコードとして記述すればよいのかを、実際のサンプルを交えながら確認していきましょう。以下の手順で進めていきます。
- マークアップできる情報の確認
- マークアップの実装
マークアップできる情報の確認
構造化データを実装する前に、まずは「どの情報を構造化できるのか」を整理することが重要です。
Organization(組織情報)の構造化データは、企業・団体としての公式情報を検索エンジンに正確に伝えることを目的としています。そのため、マークアップ対象となるのは、Webサイト上に明示されている以下のような情報です。
- 組織名(正式名称)
- 公式サイトのURL
- ロゴ画像(公式ロゴ)
- 事業内容や組織の概要
- 住所(所在地
- 電話番号や問い合わせ先
- 公式SNSアカウント(X、Facebook、LinkedIn など)
これらは、トップページや会社概要ページ、お問い合わせページなどに分散して記載されているケースが一般的です。構造化データでは、それらの情報を1つの「組織情報」としてまとめて定義することで、Googleに対して「このサイトは、こういう組織が運営している公式サイトである」と明確に伝えることができます。
そのため、実装に着手する前に、
- サイト内に公式情報として掲載されている内容は何か
- 情報に表記ゆれや古い内容が含まれていないか
- ロゴやSNSリンクは公式なものか
といった点を確認し、マークアップに使用する情報を確定させるようにしましょう。この整理を行わずに構造化データを実装すると、誤った情報を検索エンジンに伝えてしまい、信頼性(E-E-A-T)を下げる原因にもなりかねません。
マークアップの実装
ここでは、組織情報(Organization)を構造化データとして定義するための、JSON-LD形式のサンプルコードを紹介します。
【組織情報 – Organization のサンプルコード】
JSON
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "株式会社 構造化データテック",
"url": "https://www.structural-data-tech.com/",
"logo": "https://www.structural-data-tech.com/images/logo_official.png",
"sameAs": [
"https://twitter.com/struct_data_tech",
"https://www.facebook.com/structdata.tech/"
],
"contactPoint": {
"@type": "ContactPoint",
"telephone": "+81-3-1234-5678",
"contactType": "customer service"
},
"address": {
"@type": "PostalAddress",
"streetAddress": "新宿区西新宿 0-0-0",
"addressLocality": "東京都",
"addressRegion": "新宿区",
"postalCode": "160-0023",
"addressCountry": "JP"
}
}
</script>
コードのポイント
| コード | 意味 |
| @type: Organization | このページが「組織(企業)」に関する情報であることを示しています。 |
| name / url / logo | 会社名・公式サイトURL・公式ロゴといった、組織の基本情報を定義しています。 |
| sameAs | 公式SNSアカウントを指定することで、組織の実在性や信頼性を補強しています。 |
| contactPoint / address | 問い合わせ先や所在地を明示し、Googleに「公式情報」であることを伝えています。 |
上記のコードブロック全体をコピーし、対象となるHTMLファイルの<head>タグ内に貼り付ければ実装は完了です。
コードを設置したら、必ずGoogleのリッチリザルトテストツールで検証を行い、構文エラーや警告がないことを確認してください。エラーがある場合、AIによる情報採用の機会を失うだけでなく、リッチリザルトの表示資格も失うことになるため、注意しておきましょう。
構造化データの検証方法
構造化データを実装したら、必ず正しく認識されているかを確認しましょう。検証には主に次の2つの方法があります。
- 構造化データテストツール(リッチリザルトテスト)
- Search Console(サーチコンソール)
| ツール名 | 概要 | 確認できる内容 |
| 構造化データテストツール(リッチリザルトテスト) | URLまたはコードを入力するだけで、構造化データが正しく記述されているかを確認できる。 | ・構造化データの記述が正しいか ・エラーや警告(修正箇所)の特定。 |
| Search Console(サーチコンソール) | Googleが実際にクロール・インデックスしたデータに基づき、構造化データの検出状況を確認できる。 | ・構造化データの検出状況 ・実装されている構造化データの種類 ・エラーや警告(特に「拡張機能」レポート) |
今回は、サーチコンソールでの確認手順を簡単に紹介します。以下の手順で進めていきましょう。
- Search Consoleにログインし、対象プロパティを選択します。
- 左メニューの「拡張機能」から「構造化データ」または「リッチリザルト」をクリックします。
- 検出された構造化データの種類(FAQ、Article、Organizationなど)が表示されます。
- 「エラー」「警告」「有効」などのステータスを確認し、必要に応じて修正します。
- 修正後は「修正を検証」ボタンを押して再クロールを依頼します。
エラーが残っていると評価対象から外れることもあるため、検証も忘れずに行うようにしましょう。
よくあるエラーと対処法
ここでは、サーチコンソールのレポートで頻繁に表示されるエラーのうち発生頻度の高いエラーを取り上げ、原因と具体的な対処法を解説します。
無効な JSON ドキュメントです
原因
JSON-LDの構文ルールに違反しており、Googleがデータとして正しく読み取れない状態です。主に以下のような記述ミスが原因になります。
- 波括弧 {} や角括弧 [] の閉じ忘れ
- プロパティの末尾に不要なカンマ , が残っている
- 文字列が二重引用符 " で正しく囲まれていない
対処法
JSON-LDコード全体をコピーし、JSONバリデーター(JSONLintなど)に貼り付けて検証します。
構文エラーとして指摘された箇所を修正し、再度リッチリザルトテストで問題が解消されているか確認してください。
解析エラー: 「:」がありません
原因
プロパティ名と値を区切るコロン : が抜けている、もしくは記述形式が崩れている状態です。
特に、手入力でJSON-LDを作成した場合に発生しやすいエラーです。
例として、以下のような記述ミスが該当します。
- "name" "会社名" のようにコロンが抜けている
- プロパティ名や値が二重引用符で囲まれていない
対処法
各プロパティが “プロパティ名”: “値” という形式になっているかを一つずつ確認します。 エディタのシンタックスハイライトを活用すると、構文崩れに気づきやすくなります。
Unicode 文字が切り詰められています
原因
ファイルの文字コードがUTF-8以外で保存されている、またはコピー&ペースト時に不正な文字が混入している可能性があります。
特に日本語を含むJSON-LDでは、このエラーが発生するケースがあります。
対処法
以下の点を確認してください。
- HTMLファイル全体がUTF-8で保存されているか
- エディタ上で文字化けしている箇所がないか
- 全角記号や制御文字が紛れ込んでいないか
問題のある箇所は再入力し、再度検証ツールでチェックします。
構造化データのエラーは、内容そのものが評価されないだけでなく、AIによる情報理解や引用の機会を失う原因にもなります。 サーチコンソールやリッチリザルトテストを定期的に確認し、「エラーが出ていない状態」を維持することが、AIO/LLMO対策の土台を築くためにも大切です。
まとめ
構造化データは、AI検索時代において、検索エンジンや生成AIがWeb上の情報を正しく理解するための「共通の言語」となる仕組みです。AIが情報を理解し、正確に引用するための基盤であり、AIO対策の出発点でもあります。
本記事で解説した要点を整理すると、次のようになります。
- 構造化データは、Webページの「意味」をAIに伝える仕組み
- AIO(AI検索最適化)では、AIに引用されることが新たな流入経路となる
- 構造化データを実装することで、AIからの引用・リッチリザルト・E-E-A-T強化が期待できる
- Schema.orgとJSON-LDを理解し、正しい形式で記述することが重要
- 実装後はリッチリザルトテストやSearch Consoleで検証し、エラーを放置しない
- まずはOrganizationやFAQPageなど、影響の大きい構造から着手するのが現実的
検索順位だけを追う時代は終わり、これからは「AIに正しく理解され、信頼され、引用される」ことが重要になります。構造化データは、そのための最も基礎的で、かつ効果の高い施策です。
今後、AI検索が主流になるにつれ、構造化データの整備状況がサイトの評価や露出に直結していくでしょう。今のうちに正しく理解し、段階的に実装を進めることで、AIO時代における競争優位を築くことができます。

この記事を書いた人
クーシーブログ編集部
1999年に設立したweb制作会社。「ラクスル」「SUUMO」「スタディサプリ」など様々なサービスの立ち上げを支援。10,000ページ以上の大規模サイトの制作・運用や、年間約600件以上のプロジェクトに従事。クーシーブログ編集部では、数々のプロジェクトを成功に導いたメンバーが、Web制作・Webサービスに関するノウハウやハウツーを発信中。
お問い合わせはこちらから
Web制作デザイン、丸ごとお任せ
お問い合わせする
テキスト:佐々木香苗 デザイン:ピョータント
Share on
COOSYの
制作実績
UIUXと美しさを両立させた、クーシーが誇る成功事例一覧。
課題解決のアイデア満載です。